ML(MachineLearning) - 기계학습이란 무엇인가
Introduction
ML은 여러 면에서 Data Science와 Software Engineering이라는 두 분야의 교차점이다.
ML의 목표는 데이터를 사용하여 소프트웨어 애플리케이션 또는 서비스에 통합할수 있는 예측 모델을 만드는 것이다.
The goal of machine learning is to use data to create a predictive model that can be incorporated into a software application or service.
Data -> Predictive Model -> Incorporating to Software
이 목표를 실현하기 위해서,
모델을 학습 시키는데 사용할 데이터를 탐색하고 준비하는 데이터 과학자와 모델을 새 데이터 값(추론이라고 하는 프로세스)을 예측하는 데 사용되는 애플리케이션에 통합하는 소프트웨어 개발자 간의 협업이 필요하다.
ML은 데이터의 통계 및 수학 모델링의 기원을 가지고 있다.
ML의 기본 개념은 과거 관찰의 데이터를 사용하여 알 수 없는 결과 또는 값을 예측하는 것이다. 다음은 그 예시이다.
- 아이스크림 가게의 소유주proprietor는 특정 일에 그 날 일기 예보에 따라 아이스크림을 얼마나 판먀할지 예측하기 위해 핀메 기록과 날씨 기록을 결합하는 응용 프로그램을 사용할 수 있다.
- 의사는 과거 환자의 임상 데이터를 사용하여 새로운 환자가 체중, 혈당 수준 및 기타 측정과 같은 요인에 따라 당뇨병의 위험에 처해 있는지 여부를 예측하는 자동화 된 테스트를 실행할 수 있다.
- 남극의 한 연구원은 과거 관측을 사용하여 새의 플리퍼, 청구서 및 기타 물리적 특성의 측정값에 따라 다른 펭귄 종(예: 아델리, 젠투 또는 친스트랩)의 식별을 자동화할 수 있다.
Machine learning models
ML은 수학과 통계가 기반이기 때문에, ML이 수학 용어에 들어간다는 생각이 일반적이다.
기본적으로 Machine learning model은 -한개 또는 여러개의 입력으로 출력을 계산하는 함수를 캡슐화하는- software application이다.
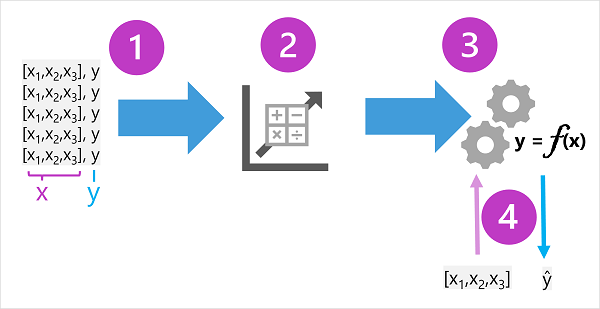
-
학습 데이터는 과거 관찰로 구성된다. 대부분의 경우 관찰에는 관찰되는 항목의 관찰된 특성 또는 특징 과 예측하도록 모델을 학습하려는 항목의 알려진 값(known as the label)이 포함된다.
{정답항목의 속성들} - 정답
{길다란 목, 얼룩무늬, 뿔} - 기린수학 용어로는 약식 변수 이름 $x$를 사용하여 특징들을 표시하고, $y$라고 하는 레이블이 자주 표시된다. 일반적으로 관찰은 여러 특징 값으로 구성되므로 $x$는 실제로 $[x_1,x_2,x_3,…]$와 같이 벡터(여러 값이 있는 배열)이다.
이를 명확히 하기 위해 앞에서 설명한 예제를 살펴보겠다.
- 아이스크림 판매 시나리오에서 우리의 목표는 날씨에 따라 아이스크림 판매 수를 예측할 수 있는 모델을 학습시키는 것이다. 하루의 날씨 측정(온도, 강우, 풍속 등)은 특징features ($x$)이고, 매일 판매되는 아이스크림의 수는 레이블 ($y$)이다.
- 의료 시나리오에서 목표는 환자가 임상 측정에 따라 당뇨병의 위험에 처해 있는지 여부를 예측하는 것이다. 환자의 측정 (체중, 혈당 수준 등)은 특징 ($x$)이며 당뇨병의 가능성 (예 : 위험에 대한 1 , 위험하지 않은 경우 0 )은 라벨 ($y$)이다.
- 남극 연구 시나리오에서는 물리적 특성에 따라 펭귄의 종을 예측하려고 한다. 펭귄의 주요 측정값(지느러미 길이, 부리 너비 등)은 특징 ($x$)이며, 종(예: 아델리는 0, 젠투는 1, 친스트랩은 2)은 레이블 ($y$)이다.
-
알고리즘은 데이터에 적용되어 특징features과 레이블 간의 관계를 확인하고, $y$를 계산하기 위해 $x$에서 수행할 수 있는 계산으로 해당 관계를 일반화한다. 사용되는 특정 알고리즘은 해결하려는 예측 문제의 종류에 따라 달라지지만(나중에 자세히 설명) 기본 원칙은 특징 값을 사용하여 레이블을 계산할 수 있는 함수에 데이터를 맞추 는 것이다.
-
알고리즘의 결과는 알고리즘에서 파생된 계산을 함수로 캡슐화하는 모델이다. f라고 하겠다. 수학 표기법:
$y = f(x)$
-
이제 학습 단계가 완료되었으므로 학습된 모델을 추론에 사용할 수 있다. 이 모델은 기본적으로 학습 프로세스에서 생성된 함수를 캡슐화하는 소프트웨어 프로그램이다. 특징features 값 집합을 입력하고 해당 레이블의 예측을 출력으로 받을 수 있다. 모델의 출력은 관찰된 값이 아니라 함수에 의해 계산된 예측이므로, 함수의 출력은 $ŷ$로 표시되는 경우가 많다(이는 “y-hat”으로 다소 유쾌하게 발음된다).
(이후 실제 관찰했던 $y$와 $ŷ$ 을 비교 -> 모델 성능 평가)
Types of machine learning model
기계 학습에는 여러 유형이 있으며 예측하려는 내용에 따라 적절한 형식을 적용해야 한다.
다음 다이어그램에는 일반적인 유형의 기계 학습에 대한 분석이 나와 있다.
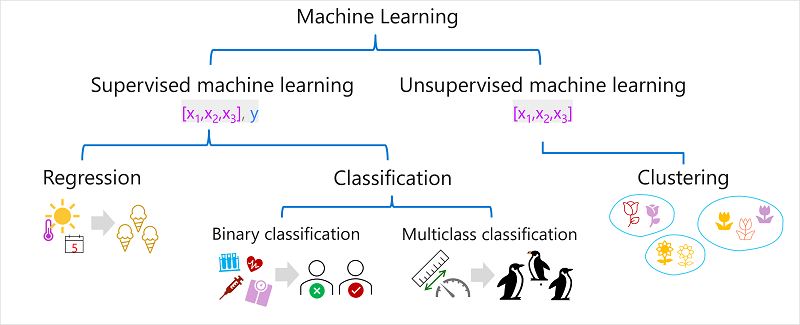
Supervised machine learning
| 감독된 기계 학습
감독되는 기계 학습은 학습 데이터에 기능 값과 알려진 레이블 값이 모두 포함된 기계 학습 알고리즘의 일반적인 용어이다. 감독된 기계 학습은 과거 관찰에서 기능과 레이블 간의 관계를 결정하여 모델을 학습시키는 데 사용되므로 향후 사례에서 알 수 없는 레이블을 기능에 대해 예측할 수 있다.
Regression 회귀
회귀 는 모델에서 예측하는 레이블이 숫자 값인 감독된 기계 학습의 한 형태이다. 다음은 그 예이다.
- 온도, 강우량 및 윈드스피드에 따라 지정된 날에 판매되는 아이스크림의 수이다.
- 부동산의 판매 가격은 제곱 피트로 계산된 크기, 포함된 침실 수, 그리고 그 위치의 사회경제적 지표에 따라 결정된다.
- 엔진 크기, 무게, 너비, 높이 및 길이에 따라 자동차의 연료 효율(갤런당 마일 단위)이다.
Classification 분류
분류 는 레이블이 분류 또는 클래스를 나타내는 감독된 기계 학습의 한 형태이다. 두 가지 일반적인 분류 시나리오가 있다.
-
Binary classification 이진 분류
이진 분류에서 레이블은 관찰된 항목이 특정 클래스의 인스턴스인지 아닌지를 결정한다. 또는 다른 방법으로 이진 분류 모델은 두 가지 상호 배타적 결과 중 하나를 예측한다. 다음은 그 예이다.
- 환자가 체중, 나이, 혈당 수준 등과 같은 임상 메트릭에 따라 당뇨병에 대한 위험에 처해 있는지 여부.
- 은행 고객이 소득, 신용 기록, 연령 및 기타 요인에 따라 대출을 상환하지 못할 가능성이 있는지 여부이다.
- 우편 목록 고객이 인구 통계 특성 및 과거 구매에 따라 마케팅 제안에 긍정적으로 응답할지 여부이다.
이러한 모든 예제에서 모델은 단일 가능한 클래스에 대해 이진 true/false 또는 긍정/음수 예측을 예측한다.
-
Multiclass classification 다중 클래스 분류
다중 클래스 분류 는 이진 분류를 확장하여 여러 가능한 클래스 중 하나를 나타내는 레이블을 예측한다. 예를 들면 다음과 같다.
- 물리적 측정을 바탕으로 펭귄의 종 (아델리, 젠투, 또는 친스트랩)을 식별한다.
- 캐스팅, 감독 및 예산을 기반으로 한 영화(코미디, 공포, 로맨스, 모험 또는 공상 과학 소설)의 장르이다.
여러 클래스의 알려진 집합을 포함하는 대부분의 시나리오에서 다중 클래스 분류는 상호 배타적인 레이블을 예측하는 데 사용된다. 예를 들어 펭귄은 젠투 와 아델리가 될 수 없다. 그러나 다중 레이블 분류 모델을 학습하는 데 사용할 수 있는 몇 가지 알고리즘도 있다. 이 알고리즘에는 단일 관찰에 대해 둘 이상의 유효한 레이블이 있을 수 있다. 예를 들어 영화는 잠재적으로 공상 과학 소설 과 코미디로 분류될 수 있다.
Unsupervised machine learning
| 감독되지 않는 기계 학습
감독되지 않는 기계 학습에는 알려진 레이블이 없는 기능 값으로만 구성된 데이터를 사용하는 학습 모델이 포함된다. 감독되지 않는 기계 학습 알고리즘은 학습 데이터에서 관찰 기능 간의 관계를 결정한다.
Clustering 클러스터링
감독되지 않는 기계 학습의 가장 일반적인 형태는 클러스터링이다. 클러스터링 알고리즘은 해당 기능을 기반으로 관찰 간의 유사성을 식별하고 개별 클러스터로 그룹화한다. 다음은 그 예이다.
- 크기, 잎 수 및 꽃잎 수에 따라 비슷한 꽃을 그룹화한다.
- 인구 통계 특성 및 구매 동작에 따라 유사한 고객 그룹을 식별한다.
어떤 면에서 클러스터링은 다중 클래스 분류와 비슷한다. 관찰을 불연속 그룹으로 분류한다. 차이점은 분류를 사용할 때 학습 데이터의 관찰이 속한 클래스를 이미 알고 있다는 것이다. 알고리즘은 기능과 알려진 분류 레이블 간의 관계를 확인하여 작동한다. 클러스터링에는 이전에 알려진 클러스터 레이블이 없으며 알고리즘은 기능의 유사성에 따라 데이터 관찰을 그룹화한다.
경우에 따라 클러스터링을 사용하여 분류 모델을 학습하기 전에 존재하는 클래스 집합을 확인한다. 예를 들어 클러스터링을 사용하여 고객을 그룹으로 분할한 다음 해당 그룹을 분석하여 다양한 고객 클래스(높은 값 - 낮은 볼륨, 빈번한 소량 구매자 등)를 식별하고 분류할 수 있다. 그런 다음 분류를 사용하여 클러스터링 결과의 관찰에 레이블을 지정하고 레이블이 지정된 데이터를 사용하여 새 고객이 속할 수 있는 고객 범주를 예측하는 분류 모델을 학습할 수 있다.